How it works#
📏 Leveraging LLM Context Windows#
ContextGem leverages LLMs’ long context windows to deliver superior extraction accuracy. Unlike RAG approaches that often struggle with complex concepts and nuanced insights, ContextGem is betting on the continuously expanding context capacity, evolving capabilities of modern LLMs, and constantly decreasing LLM costs. This approach enables direct information extraction from full documents, eliminating retrieval inconsistencies and capturing the complete context necessary for accurate understanding.
🧩 Core Components#
ContextGem’s main elements are the Document, Aspect, and Concept models:
📄 Document#
Documentmodel contains text and/or visual content representing a specific document. Documents can vary in type and purpose, including but not limited to:Contracts: legal agreements defining terms and obligations.
Invoices: financial documents detailing transactions and payments.
Curricula Vitae (CVs): resumes outlining an individual’s professional experience and qualifications.
General documents: any other types of documents that may contain text or images.
🔍 Aspect#
Aspectmodel contains text representing a defined area or topic within a document (or another aspect) that requires focused attention. Each aspect reflects a specific subject or theme. For example:Contract aspects: payment terms, parties involved, or termination clauses.
Invoice aspects: due dates, line-item breakdowns, or tax details.
CV aspects: work experience, education, or skills.
Aspects may have sub-aspects, for more granular extraction with nested context. This hierarchical structure allows for progressive refinement of focus areas, enabling precise extraction of information from complex documents while maintaining the contextual relationships between different levels of content.
💡 Concept#
- Concept model contains a unit of information or an entity, derived from an aspect or the broader document context. Concepts represent a wide range of data points and insights, from simple entities (names, dates, monetary values) to complex evaluations, conclusions, and answers to specific questions. Concepts can be:
Factual extractions: such as a penalty clause in a contract, a total amount due in an invoice, or a certification in a CV.
Analytical insights: such as risk assessments, compliance evaluations, or pattern identifications.
Reasoned conclusions: such as determining whether a document meets specific criteria or answers particular questions.
Interpretative judgments: such as ratings, classifications, or qualitative assessments based on document content.
Concepts may be attached to an aspect or a document. The context for the concept extraction will be the aspect or document, respectively. This flexible attachment allows for both targeted extraction from specific document sections and broader analysis across the entire document content. When attached to aspects, concepts benefit from the focused context, enabling more precise extraction of domain-specific information. When attached to documents, concepts can leverage the complete context to identify patterns, anomalies, or insights that span multiple sections.
Multiple concept types are supported: StringConcept, BooleanConcept, NumericalConcept, DateConcept, JsonObjectConcept, RatingConcept, LabelConcept
Document |
Aspect |
Sub-aspect |
Concept |
|
|---|---|---|---|---|
Legal |
Software License Agreement |
Intellectual Property Rights |
Patent Indemnification |
Indemnification Coverage Scope ( |
Financial |
Quarterly Earnings Report |
Revenue Analysis |
Regional Performance |
Year-over-Year Growth Rate ( |
Healthcare |
Medical Research Paper |
Methodology |
Patient Selection Criteria |
Inclusion/Exclusion Validity ( |
Technical |
System Architecture Document |
Security Framework |
Authentication Protocols |
Implementation Risk Rating ( |
HR |
Employee Handbook |
Leave Policy |
Parental Leave Benefits |
Eligibility Start Date ( |
🔄 Extraction Workflow#
ContextGem uses the following models to extract information from documents:
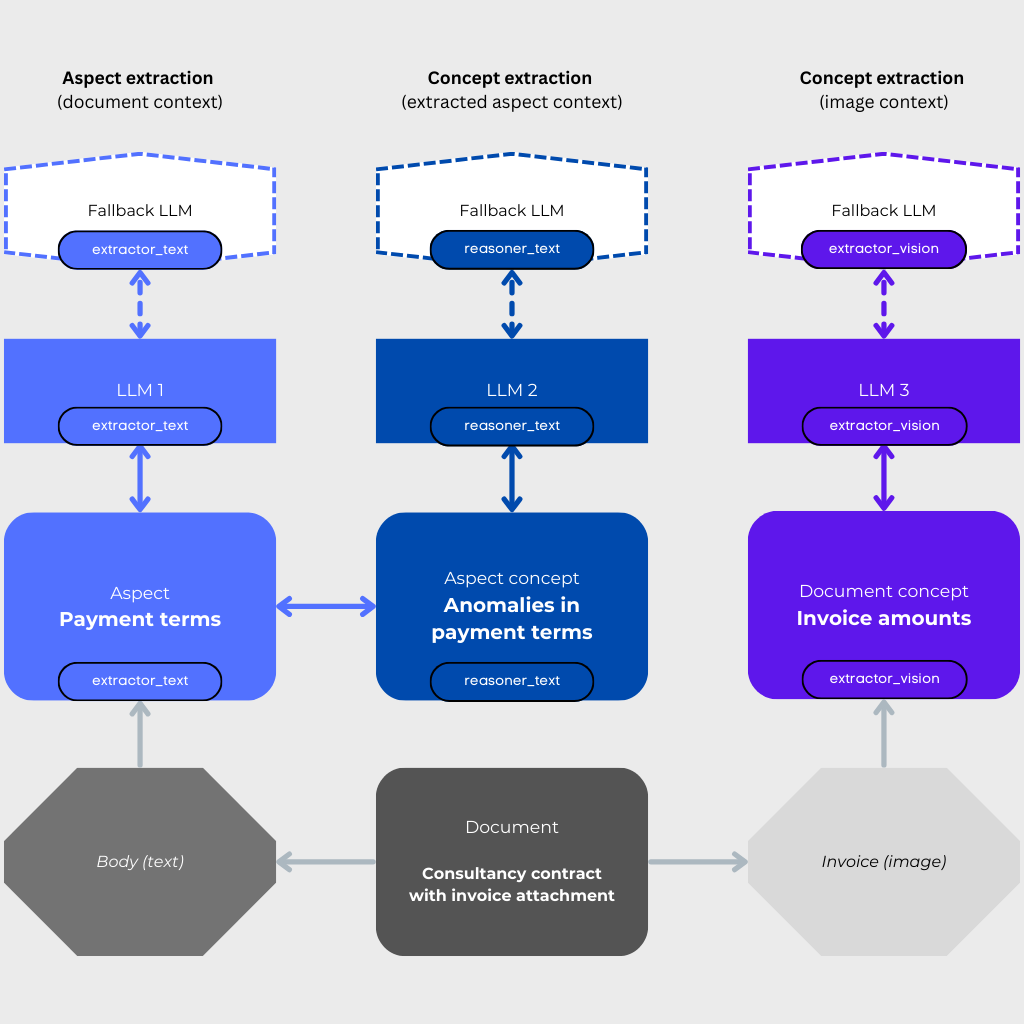
🤖 DocumentLLM#
A single configurable LLM with a specific role to extract specific information from the document.
The role of an LLM is an abstraction used to assign various LLMs tasks of different complexity. For example, if an aspect/concept is assigned llm_role="extractor_text", this aspect/concept is extracted from the document using the LLM with role="extractor_text". This helps to channel different tasks to different LLMs, ensuring that the task is handled by the most appropriate model. Usually, domain expertise is required to determine the most appropriate role for a specific aspect/concept. But for simple use cases, when working with text-only documents and a single LLM, you can skip the role assignment completely, in which case the role will default to "extractor_text".
An LLM can have a configurable fallback LLM with the same role.
See DocumentLLM for more details.
🤖🤖 DocumentLLMGroup#
A group of LLMs with different unique roles to extract different information from the document.
For more complex and granular extraction workflows, an LLM group can be used to extract different information from the same document using different LLMs with different roles. For example, a simpler LLM e.g. gpt-4o-mini can be used to extract specific aspects of the document, and a more powerful LLM e.g. o3-mini will handle the extraction of complex concepts that require reasoning over the aspects’ context.
Each LLM can have its own backend and configuration, and one fallback LLM with the same role.
See DocumentLLMGroup for more details.
Note
🧠 Only LLMs that support reasoning (chain of thought) should be assigned reasoning roles ("reasoner_text", "reasoner_vision"). For such models, internal prompts include reasoning-specific instructions intended for these models to produce higher-quality responses.
Note
👁️ Only LLMs that support vision can be assigned vision roles (e.g., "extractor_vision", "reasoner_vision").
LLM 1 ( |
LLM 2 ( |
LLM 3 ( |
|
|---|---|---|---|
Model |
gpt-4.1-mini |
o4-mini |
gpt-4.1-mini |
Task |
Extract payment terms from a contract |
Detect anomalies in the payment terms |
Extract invoice amounts |
Fallback LLM (optional) |
gpt-4o-mini |
o3-mini |
gpt-4o-mini |
ℹ️ What ContextGem Doesn’t Offer (Yet)#
While ContextGem excels at structured data extraction from individual documents, it’s important to understand its intentional design boundaries:
Not a RAG framework#
ContextGem focuses on in-depth single-document analysis, leveraging long context windows of LLMs for maximum accuracy and precision. It does not offer RAG capabilities for cross-document querying or corpus-wide information retrieval. For these use cases, traditional RAG systems such as LlamaIndex remain more appropriate.
Not an agent framework#
ContextGem is not designed as an agent framework. Based on our research into practical extraction workflows, we believe that in-depth single-document data extraction can be handled more efficiently with non-agentic LLM workflows. For use cases that require agents, we recommend using frameworks like LangChain. ContextGem can still be easily integrated as a tool within agent frameworks due to its simple API and clear output structure, making it an excellent choice for document extraction tasks within larger agent-based systems.